Paper implementation
Fast Image Search for Learned Metrics, CVPR, 2008
Fast Image Search for Learned Metrics, CVPR, 2008
For CS576 project #2, I implemented "Fast Image Search for Learend Metrics". For evaluation, I used local patch descriptors provided from Photo Tourism project[3].
Approach
This paper proposed learning a Mahalanobis distance matrix A, positive-definite d by d matrix, with pairs of similar/dissimilar points and initial distance matrix A0 (identity matrix in this paper). Squared Mahalanobis distance is represented as follow: d(x, y) = (x - y)'A(x - y).
Experiment
I evaluated this paper by indexing local patch descriptors provided from Photo Tourism project[3]. To learn metrics we gather constratins from 10K matching and non-matching patch pairs from the Trevi and Halfdome data. All methods are tested on 10K pairs from the Notre Dame data. I extracted both the raw patch intensities (4096 dim) and SIFT descriptors (128 dim) from each patch. To reduce experiment time, I reduce the dimension of raw patch intensities to 1024 dim. Then I retrieved patches with L2 baseline and learned metrics for each representation.
To determine the parameter gamma, I performed validation with 1K pairs from the training set sevral times with parameters 10^[-10:5]. I found that the best number for parameter gamma of ITML is 0.000001 for RAW data and 0.001 for SIFT data.
Results
ROC curves
| My implementation | Result in the paper | |
| ROC curves |
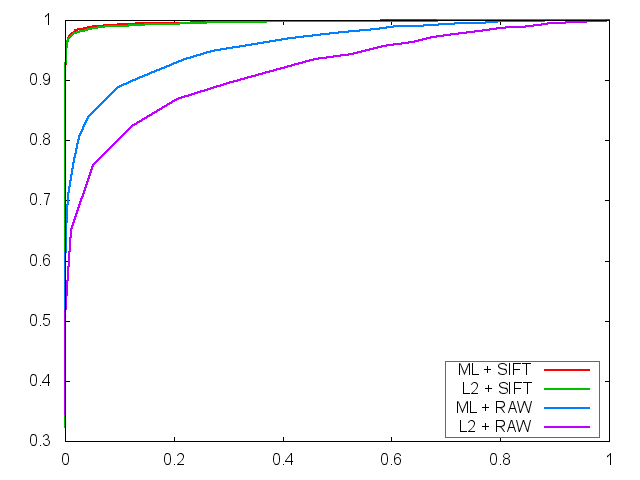
|

|
| AUC |
ML + SIFT = 0.997117 L2 + SIFT = 0.996311 ML + Raw = 0.961888 L2 + Raw = 0.928261 |
|
| false positive rate at 95% of the true positives |
ML + SIFT = 0.20 L2 + SIFT = 0.24 ML + Raw = 26.9 L2 + Raw = 52.7 |
ML + SIFT = 14.7 L2 + SIFT = 16.7 ML + Raw = 23.4 L2 + Raw = 31.1 |
Discussion
The absolute values in my results are different from that of the paper. Overall performance of SIFT is higher and that of RAW is lower in my implementation. First one is because I didn't jitter the images. Second one is mainly because we reduced the dimensionality of raw data by averaging neighbor pixels. But the trend of results of the paper and mine is similar. Our learned metrics with ITML performs better in terms of search accuracy than L2 distance metric.
It seems not scalable because it takes very long time to compute new matrix A with high dimensional data (4096 dim in the RAW case). Training a metric for RAW data with 10K constraints takes about 1 hours and it increases cubically (d ^ 3) to the dimensionality of data.
References
Code and executable
Project homepage
Tools and Libraries
Reference papers
[1] P. Jain, B. Kulis, K. Grauman, "Fast Image Search for Learned Metrics", CVPR, 2008
[2] Jason V. Davis and Brian Kulis and Prateek Jain and Suvrit Sra and Inderjit S. Dhillon, "Information Theoretic Metric Learning", ICML, 2007
[3] Noah Snavely, Steven M. Seitz, Richard Szeliski, "Photo tourism: Exploring photo collections in 3D," ACM ToG, 2006